Contributor Guide¶
This guide covers the process of contributing to Horovod as a developer.
Environment Setup¶
Clone the repository locally:
$ git clone --recursive https://github.com/horovod/horovod.git
Develop within a virtual environment to avoid dependency issues:
$ python3 -m venv env
$ . env/bin/activate
We recommend installing package versions that match with those under test in
Buildkite.
The following versions are recommended (see default versions defined through ARG in
Dockerfile.test.cpu and
Dockerfile.test.gpu file.
You can find all other non-Python packages that need to be installed on your system for Horovod to build
in the Dockerfile.test.cpu and
Dockerfile.test.gpu files.
Specifically, see all RUN apt-get install lines.
Build and Install¶
From inside the Horovod root directory, install Horovod in develop/editable mode:
$ HOROVOD_WITH_PYTORCH=1 HOROVOD_WITH_TENSORFLOW=1 pip install -v -e .
Set HOROVOD_WITHOUT_[FRAMEWORK]=1 to disable building Horovod plugins for that framework.
This is useful when you’re testing a feature of one framework in particular and wish to save time.
Set HOROVOD_WITH_[FRAMEWORK]=1 to generate an error if the Horovod plugin for that framework failed to build.
Set HOROVOD_DEBUG=1 for a debug build with checked assertions, disabled compiler optimizations etc.
Other environmental variables can be found in the install documentation.
You can install optional dependencies defined in setup.py by adding brackets
at the end of the command line e.g. [test] for test dependencies.
If you have not installed specific DL frameworks yet, add [dev] to install the CPU version of all supported DL frameworks.
In develop mode, you can edit the Horovod source directly in the repo folder. For Python code, the changes will take effect
immediately. For C++/CUDA code, the ... pip install -v -e . command needs to be invoked again to perform an incremental build.
Testing¶
Horovod has unit tests for all frameworks under test/parallel. These should be invoked via horovodrun or
mpirun and each test script may require to be run independently from the other test scripts:
$ cd test/parallel
$ horovodrun -np 2 pytest -v test_tensorflow.py
$ horovodrun -np 2 pytest -v test_torch.py
# ...
# Or to run all framework tests:
$ cd test/parallel
$ ls -1 test_*.py | xargs -n 1 horovodrun -np 2 pytest -v
Moreover, there are integration tests and non-parallelized tests to be run directly via pytest:
$ cd test/integration
$ pytest -v
$ cd test/single
$ pytest -v
Note: You will need PySpark and Java to run the Spark tests.
IMPORTANT: Some tests contain GPU-only codepaths that will be skipped if running without GPU support or, in some cases, if there are fewer than four GPUs installed.
Continuous Integration¶
Horovod uses Buildkite for continuous integration in AWS running on both Intel CPU hardware and NVIDIA GPUs (with NCCL). Tests are run once per night on master automatically, and on each commit to a remote branch.
Buildkite test configurations are defined in docker-compose.test.yml. Each test configuration defines a Docker image that is built from either Docker.test.cpu (for CPU tests) or Docker.test.gpu (for GPU tests).
Individual tests are run on each configuration as defined in
gen-pipeline.sh. Every test
configuration needs to also be defined here in order to be run at test time. Each time run_test is called
a new test artifact will be generated in Buildkite that either succeeds or fails depending on exit code.
In our AWS configuration, GPU tests are run with 4 GPUs per container. Most tests are run with 2 worker processes each, however, model parallelism require 2 GPUs per worker, requiring 4 GPUs total.
Documentation¶
The Horovod documentation is published to https://horovod.readthedocs.io/.
Those HTML pages can be rendered from .rst files located in the docs directory.
You need to set up Sphinx before you compile the documentation the first time:
$ cd docs
$ pip install -r requirements.txt
$ make clean
Then you can build the HTML pages and open docs/_build/html/index.html:
$ cd docs
$ make html
$ open _build/html/index.html
Sphinx can render the documentation in many other formats. Type make to get a list of available formats.
Adding Custom Operations¶
Operations in Horovod are used to transform Tensors across workers. Horovod currently supports operations that implement Broadcast, Allreduce, and Allgather interfaces. Gradients in Horovod are aggregated through Allreduce operations (with the exception of sparse gradients, which use Allgather).
All data transfer operations are implemented in the horovod/common/ops directory. Implementations are organized by the collective communication library used to perform the operation (e.g., mpi_operations.cc for MPI).
To create a new custom operation, start by defining a new class that inherits from the base operation, in the file corresponding to the library you’ll use to implement the operation:
class CustomAllreduce : public AllreduceOp {
public:
CustomAllreduce(MPIContext* mpi_context, HorovodGlobalState* global_state);
virtual ~CustomAllreduce() = default;
Status Execute(std::vector<TensorTableEntry>& entries, const Response& response) override;
bool Enabled(const ParameterManager& parameter_manager,
const std::vector<TensorTableEntry>& entries,
const Response& response) const override;
The Execute member function is responsible for performing the operation on a list of Tensors. The entries
parameter provides access to all the Tensor buffers and metadata that need to be processed,
and the response parameter contains additional metadata including which devices are being used by different ranks.
Enabled should return true if your operation can be performed on the given Tensor entries subject to the
current parameter settings and response metadata.
Once you’ve written the implementation for your operation, add it to the OperationManager in the
CreateOperationManager function of
operations.cc. Because more than one
operation may be enabled at a time, but only one will be performed on a given vector of Tensor entries, consider the
order of your operation in the OperationManager vector before adding it in.
The first operations in the vector will be checked before those at the end, and the first operation that is enabled will be performed. Broadly, the order of operations should be:
Custom operations that trigger based on parameters configured at runtime (e.g.,
NCCLHierarchicalAllreduce).Accelerated operations that take advantage of specialized hardware where available (e.g.,
NCCLAllreduce).Default operations that can run using standard CPUs and host memory (e.g.,
MPIAllreduce).
Most custom operations that require preconditions such as runtime flags will fall into the first category.
Adding Compression Algorithms¶
Gradient compression is used to reduce the amount of data sent over the network during an Allreduce operation. Such
compression algorithms are implemented per framework (TensorFlow, PyTorch, MXNet, etc.) in
horovod/[framework]/compression.py
(see: TensorFlow,
PyTorch).
To implement a new compression algorithm, first add a new class inheriting from Compressor:
class CustomCompressor(Compressor):
@staticmethod
def compress(tensor):
# do something here ...
return tensor_compressed, ctx
@staticmethod
def decompress(tensor, ctx):
# do something here ...
return tensor_decompressed
The compress method takes a Tensor gradient and returns it in its compressed form, along with any additional context
necessary to decompress the tensor back to its original form. Similarly, decompress takes in a compressed tensor
with its context and returns a decompressed tensor. Compression can be done in pure Python, or in C++ using a custom
op (e.g., in mpi_ops.cc for
TensorFlow).
Once implemented, add your Compressor subclass to the Compressor class, which emulates an enumeration API:
class Compression(object):
# ...
custom = CustomCompressor
Finally, you can start using your new compressor by passing it to the DistributedOptimizer:
opt = hvd.DistributedOptimizer(opt, compression=hvd.Compression.custom)
Horovod on Spark¶
The horovod.spark package makes it easy to run Horovod jobs in Spark clusters. The following section
outlines how Horovod orchestrates Spark and MPI.
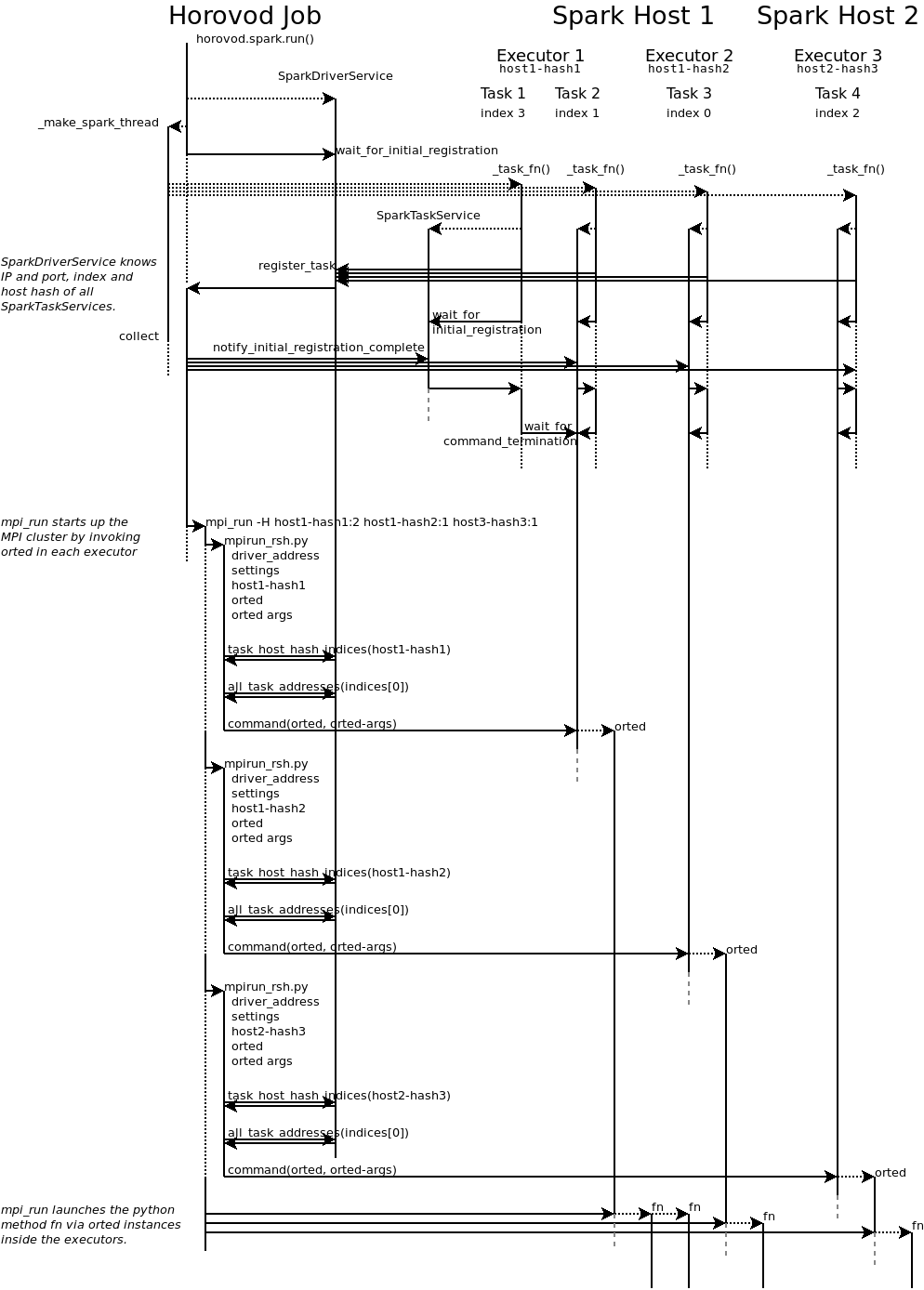
Your Horovod job becomes the Spark driver and creates num_proc tasks on the Spark cluster (horovod.spark._make_spark_thread).
Each task runs horovod.spark._task_fn that registers with the driver, so that the driver knows when all
tasks are up and which IP and port they are running at. They also send their host hash, a string that
is treated by MPI as a hostname.
Note: Horovod expects all tasks to run at the same time, so your cluster has to provide at least num_proc cores to your Horovod job.
There can be multiple cores per executor, so an executor can process multiple tasks. Hosts can also have multiple executors.
The driver signals all tasks that all other tasks are up running. Each task continues initialisation and then waits for the RPC to terminate.
After signalling all tasks are up, the driver runs mpi_run to launch the Python function in those tasks (RPC).
Usually, MPI connects to the hosts via SSH, but this would not allow to launch the Python function inside the Spark executors.
Therefore, MPI connects to each executor by invoking the horovod.spark.driver.mpirun_rsh method to “remote shell”
into the executors. This method communicates with the task that has the smallest index per host hash.
This task executes the orted command provided by MPI.
This way, a single orted process runs per executor, even if the executor has multiple cores / tasks.
MPI then uses orted to launch the Python function for that executor.
There will be one Python function running per core in each executor inside the first task.
All other tasks with the same host hash wait for the first task to terminate.
The following diagram illustrates this process:
Elastic Horovod on Spark¶
Elastic Horovod on Spark has a few constraints:
each host has at most a single slot, which simplifies auto-scaling on Spark - for this the host hash includes the index of the task - this dis-allows shared memory across tasks running on the same host - see “Host Hash” below.
Host Hash¶
The host hash represents a single unit of processing power that shares memory. Usually, this is a regular host. In scenarios where YARN is used to allocate cores for your Spark job, memory allocation is only shared within an executor. There can be multiple executors running for your Horovod job on the same host, but they have each limited memory allocation. Hence each executor gets its own host hash.
If you require each Python function to run in their own task process within a Spark executor, then the index of the task has to become part of the host hash as well. This has only been shown useful for Elastic Horovod on Spark, but there only for simplification.
Release Process¶
This section applies to contributors with permissions to release new versions of Horovod to the public.
Tag¶
$ git tag -a v0.18.0 -m "Horovodrun config file, bugfixes"
$ git push origin v0.18.0
Create Release¶
Follow the GitHub instructions for Creating a Release.
Once the release has been created, this will trigger a workflow that uploads the Horovod source distribution to PyPI automatically using Twine.
After the workflow completes, verify that the latest version of Horovod is now available:
$ pip install --upgrade horovod