Distributed Hyperparameter Search¶
Horovod’s data parallelism training capabilities allow you to scale out and speed up the workload of training a deep learning model. However, simply using 2x more workers does not necessarily mean the model will obtain the same accuracy in 2x less time.
To address this, you often need to re-tune hyperparameters when training at scale, as many hyperparameters exhibit different behaviors at larger scales.
Horovod offers a Ray Tune integration to enable parallel hyperparameter tuning with distributed training.

Ray Tune is an industry standard tool for distributed hyperparameter tuning. Ray Tune includes the latest hyperparameter search algorithms, integrates with TensorBoard and other analysis libraries, and natively supports distributed training. The Ray Tune + Horovod integration leverages the underlying Ray framework to provide a scalable and comprehensive hyperparameter tuning setup.
By the end of this guide, you will learn:
How to set up Ray Tune and Horovod to tune your hyperparameters
Typical hyperparameters to configure for distributed training
Horovod + Ray Tune¶
Leverage Ray Tune with Horovod to combine distributed hyperparameter tuning with distributed training. Here is an example demonstrating basic usage:
import horovod.torch as hvd
from ray import tune
import time
def training_function(config: Dict):
hvd.init()
for i in range(config["epochs"]):
time.sleep(1)
model = Model(learning_rate=config["lr"])
tune.report(test=1, rank=hvd.rank())
trainable = DistributedTrainableCreator(
training_function, num_slots=2, use_gpu=use_gpu)
analysis = tune.run(
trainable,
num_samples=2,
config={
"epochs": tune.grid_search([1, 2, 3]),
"lr": tune.grid_search([0.1, 0.2, 0.3]),
}
)
print(analysis.best_config)
Basic setup¶
Use Ray Tune’s DistributedTrainableCreator function to adapt your Horovod training function to be compatible with Ray Tune.
DistributedTrainableCreator exposes num_hosts, num_slots, use_gpu, and num_cpus_per_slot. Use these parameters to specify the resource allocation of a single “trial” (or “Trainable”) which itself can be a distributed training job.
# Each training job will use 2 GPUs.
trainable = DistributedTrainableCreator(
training_function, num_slots=2, use_gpu=True)
The training function itself must do three things:
It must adhere to the Tune Function API signature.
Its body must include a
horovod.init()call.It must call
tune.report(docs) during training, typically called iteratively at the end of every epoch.
Optimization of hyperparameters¶
Ray Tune is able to orchestrate complex computational patterns with the Ray Actor API. For hyperparameter tuning, Ray Tune is able to conduct parallel bayesian optimization and Population Based Training on a group of distributed models.
You may need to implement model checkpointing. The rest of the optimization process can be configured with a couple lines of code.
from ray import tune
from ray.tune.suggest.bayesopt import BayesOptSearch
from ray.tune.suggest import ConcurrencyLimiter
def training_function(config):
...
algo = BayesOptSearch()
algo = ConcurrencyLimiter(algo, max_concurrent=4)
results = tune.run(
training_function,
config={"lr": tune.uniform(0.001, 0.1)},
name="horovod",
metric="mean_loss",
mode="min",
search_alg=algo)
print(results.best_config)
Search Space
Tune has a native interface for specifying search spaces. You can specify the search space via tune.run(config=...).
Thereby, either use the tune.grid_search primitive to specify an axis of a grid search…
tune.run(
trainable,
config={"bar": tune.grid_search([True, False])})
… or one of the random sampling primitives to specify distributions:
tune.run(
trainable,
config={
"param1": tune.choice([True, False]),
"bar": tune.uniform(0, 10),
"alpha": tune.sample_from(lambda _: np.random.uniform(100) ** 2),
"const": "hello" # It is also ok to specify constant values.
})
Read more about Tune’s Search Space API.
Analyzing Results
tune.run returns an Analysis object which has methods for analyzing your training.
analysis = tune.run(trainable, search_alg=algo, stop={"training_iteration": 20})
best_trial = analysis.best_trial # Get best trial
best_config = analysis.best_config # Get best trial's hyperparameters
best_logdir = analysis.best_logdir # Get best trial's logdir
best_checkpoint = analysis.best_checkpoint # Get best trial's best checkpoint
best_result = analysis.best_result # Get best trial's last results
best_result_df = analysis.best_result_df # Get best result as pandas dataframe
Set up a tuning cluster¶
Leverage Ray Tune with Horovod on a laptop, single machine with multiple GPUs, or across multiple machines. To run on a single machine, execute your Python script as-is (for example, horovod_simple.py, assuming Ray and Horovod are installed properly):
python horovod_simple.py
To leverage a distributed hyperparameter tuning setup with Ray Tune + Horovod, install Ray and set up a Ray cluster. Start a Ray cluster with the Ray Cluster Launcher or manually.
Below, we’ll use the Ray Cluster Launcher, but you can start Ray on any list of nodes, on any cluster manager or cloud provider.
First, specify a configuration file. Below we have an example of using AWS EC2, but you can launch the cluster on any cloud provider:
# ray_cluster.yaml
cluster_name: horovod-cluster
provider: {type: aws, region: us-west-2}
auth: {ssh_user: ubuntu}
min_workers: 3
max_workers: 3
# Deep Learning AMI (Ubuntu) Version 21.0
head_node: {InstanceType: p3.2xlarge, ImageId: ami-0b294f219d14e6a82}
worker_nodes: {
InstanceType: p3.2xlarge, ImageId: ami-0b294f219d14e6a82}
setup_commands: # Set up each node.
- HOROVOD_WITH_GLOO=1 HOROVOD_GPU_OPERATIONS=NCCL pip install horovod[ray]
Run ray up ray_cluster.yaml, and a cluster of 4 nodes (1 head node + 3 worker nodes) will be automatically started with Ray.
[6/6] Starting the Ray runtime
Did not find any active Ray processes.
Shared connection to 34.217.192.11 closed.
Local node IP: 172.31.43.22
2020-11-04 04:24:33,882 INFO services.py:1106 -- View the Ray dashboard at http://localhost:8265
--------------------
Ray runtime started.
--------------------
Next steps
To connect to this Ray runtime from another node, run
ray start --address='172.31.43.22:6379' --redis-password='5241590000000000'
Alternatively, use the following Python code:
import ray
ray.init(address='auto', _redis_password='5241590000000000')
If connection fails, check your firewall settings and network configuration.
To terminate the Ray runtime, run
ray stop
Shared connection to 34.217.192.11 closed.
New status: up-to-date
Useful commands
Monitor autoscaling with
ray exec ~/dev/cfgs/check-autoscaler.yaml 'tail -n 100 -f /tmp/ray/session_latest/logs/monitor*'
Connect to a terminal on the cluster head:
ray attach ~/dev/cfgs/check-autoscaler.yaml
Get a remote shell to the cluster manually:
ssh -o IdentitiesOnly=yes -i ~/.ssh/ray-autoscaler_2_us-west-2.pem ubuntu@34.217.192.11
After the cluster is up, you can ssh into the head node and run your Tune script there.
Implementation (underneath the hood)¶
Underneath the hood, Ray Tune will launch multiple “trials” in parallel. Each of these trials reference a set of Ray actors. For each trial, there will be 1 “coordinator actor,” and this coordinator actor will manage N training actors. One basic assumption of this implementation is that all sub-workers of a trial will be placed evenly across different machines.
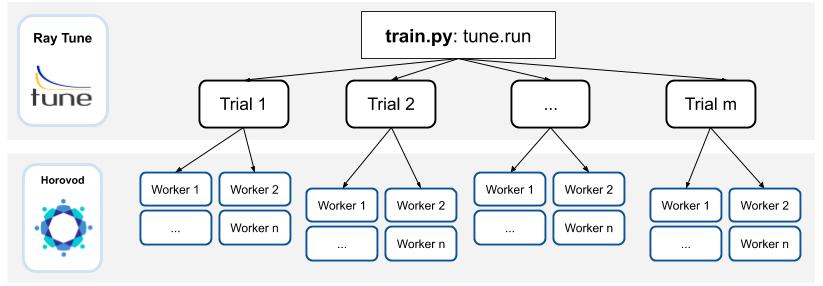
Training actors will each hold a copy of the model and will create a communication group for Horovod allreduce. Training will execute on each actor, reporting intermediate metrics back to Tune.
This API requires Gloo as the underlying communication primitive. Be sure to install Horovod with HOROVOD_WITH_GLOO enabled.
Common Hyperparameters¶
We will cover a couple common hyperparameters that you may need to re-tune at scale:
Batch Size
Learning Rate schedules
Optimizers
Parameter: Batch size¶
By using data parallelism, it is necessary to scale the batch size along with workers to avoid reducing the per-worker workload and maximizing worker efficiency. However, increasing batch size can easily cause generalization issues (see this Facebook Imagenet Training paper for more details).
What are common solutions?
Linear scaling of learning rates: When the minibatch size is multiplied by k, multiply the learning rate by k.
Dynamically adjusting batch size over the course of training:
One of the original papers presents a simple baseline of increasing the batch size over time
ABSA provides a way to leverage second order information to guide the batch size over time
Gradient noise scale can be calculated to guide the increase of batch size over time
To leverage a dynamically changing batch size in training, you should either:
Leverage gradient accumulation
Implement your own TrialScheduler to dynamically change the number of workers (coming soon)
Parameter: Learning rate schedules (warmup)¶
As noted in this Facebook Imagenet Training paper, the linear scaling rule breaks down when the network is rapidly changing, which commonly occurs in early stages of training. This issue can be addressed with a “warmup,” which is a strategy of using less aggressive learning rates at the start of training.
What are common solutions?
Goyal et al. (2017) proposes a warm-up schedule, where training usually starts with a small learning rate, and gradually increased to match a larger target learning rate. After the warm-up period (usually a few epochs), a regular learning rate schedule is used (“multi-steps”, polynomial decay etc). Thus, there are generally three parameters for warmup schedule:
Length of warmup (number of epochs)
Starting learning rate
Peak learning rate
Parameter: Optimizers¶
Optimizers are algorithms/methods that are used to update network weights iteratively. Common optimizers in deep learning include Adam, RMSProp, and SGD with momentum.
In large scale learning, naive approaches to optimizing and updating neural network weights can lead to poor generalization or decreased performance. For example, Alexnet on Imagenet using standard SGD with momentum (and a warmup scheme) will stop scaling after B=2K.
What are common solutions?
LARS calculates a local learning rate per layer at each optimization step. It normalizes the gradient magnitude of each layer and instead uses a user-set coefficient and magnitude of the layer weights to compute the learning rate. The original paper for LARS presents performance improvements for training AlexNet with large batch sizes.
LAMB stands for “Layer-wise Adaptive Moments optimizer for Batch training.” It makes a few small changes to LARS. In spirit, it is “combining the ADAM optimizer with layer-wise scaling of LARS”. The original motivation of the LAMB work is because LARS did not work well for attention-based architectures such as BERT.